Tabela de dispersão (também conhecida por ou tabela hash, do inglês hash) é uma estrutura de dados especial, que associa chaves de pesquisa a valores.
O seu objetivo é: a partir de uma chave simples, fazer uma busca rápida e obter o valor desejado.
Tabelas de dispersão são normalmente utilizadas para implementar vetores associativos, conjuntos e caches.
complexidade:

O "ganho" com relação a outras estruturas associativas (como um vetor simples) passa a ser maior conforme a quantidade de dados aumenta.
Função de espalhamento

O ideal para a função de espalhamento é que sejam sempre fornecidos
índices únicos para as chaves de entrada.
A função perfeita seria a que,
para quaisquer entradas A e B, sendo A diferente de B, fornecesse
saídas diferentes.
Quando as entradas A e B são diferentes e, passando
pela função de espalhamento, geram a mesma saída, acontece o que
chamamos de colisão.
- Método da divisão (método da congruência linear)

- Potências de dois devem ser evitadas para valores de
.
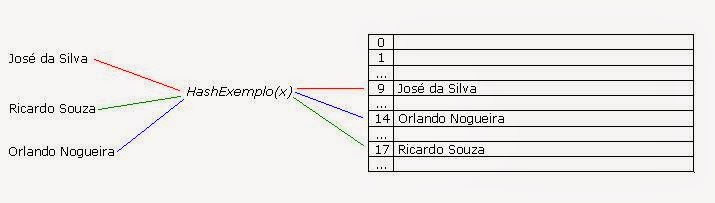
Exemplo:
- José da Silva;
- Ricardo Sousa
- Orlando Nogueira
Renato Porto
e temos uma colisão!

Se inserirmos um outro nome começado com a letra R, teremos uma outra colisão na letra R. Se inserirmos "João Siqueira", a entrada estaria em conflito com o "José da Silva".



